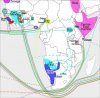
Ich sollte wohl noch mal erläutern, was mich u.a. auf das Thema gebracht hat: Im Phönizier-Faden hatte ich, bevor dieser endgültig in seichte Gewässer geriet, hier und hier "merkwürdige" interkontinentale Sprachverbindungen aus dem lexikostatistisch erstellen World Language Tree referiert. Da ich nicht sämtliche amerindische, afrikanische und neuguineische Sprachen auf Anhieb geographisch lokalisieren kann, habe ich mir die Mühe gemacht, diverse dieser Sprachverbindungen zu kartieren (Anlage). Nicht vollständig, dazu sind es zu viele, irgendwann gingen mir Lust und unterscheidbare Farben aus, aber wohl schon die meisten.
Das entstandene Muster ist zugegebenermaßen nicht nut auf den ersten Blick verwirrend. Klar wird jedoch, daß, wenn auch nur ein Teil der lexikostatistisch ermittelten Beziheungen eingehenderer Überprüfung standhält, deutlich mehr auf den Ozeanen los war als in den Geschichtsbüchern steht. Und zwar nicht nur transpazifisch, ondern auch und v.a. über Indischen Ozean und Atlantik. Ins Blickfeld rücken insbesondere Neuguinea mit seiner hohen linguistischen Diversität, dazu (Alt-)Guinea, weniger Guyana, dafür aber das ebenfalls linguistisch hoch diverse Amazonien. Angemerkt sei, daß die transpazifischen Beziehungen v.a. von Neuguinea, daneben Südostasien (Tai-Kadai, Taiwan) ausgehen, während lexikostatistisch die meisten der "üblichen Verdächtigen" für die Erstbesiedlung Amerikas (Tungusen, Japaner, Ainu etc.) ihren Weg dorthin über Indischen Ozean und Atlantik fanden.
In Erweiterung habe ich die spanische 100-Vokabel-Liste gegen Deutsch geprüft, wobei ich nun auch die o.g. Fälle als korrespondierend einbezog, und erhielt einem Wert von nur noch 31%. Dies zeigt, daß, trotz der geringen Grundgesamtheit, die verwendeten 40 Grundvokabeln tendenziell geeignet sind, einen zutreffenden Eindruck der lexikalischen Nähe zweier Sprachen zu vermitteln.
Nun zu den Stichproben:
A. Mande-Sprachen (Westafrika, Niger-Kongo) -- Mandi (Marienberg-Sprachen, Neuguinea), hellblau in der Karte: Die Namensähnlichkeit war verlockend, und die geograühische Relation interessant. Hier die mir plausibel bzw. spekulaitiv denkbar erscheinenden Kognate (Mandinka-Mandi, soweit nicht anders angegeben; Soninka ist eine weitere Mande-, Bungain eine weitere Marienberg-Sprache):
B. Nihali (Indien)- Wolof (Senegal), grünblau in der Karte: Nihali enthält etwa 25-30% vor-indoaryanisches, vor-dravidisches und vor-austrosiatisches Substrat, und gilt damit als bester Repräsentant frühneolithischer südasiatischer Sprachen (Indus-Kultur). Über mögliche Verbindung zum Sumerischen wird spekuliert. Linguistische Verbindung nach Westafrika (hier ohne transatlantische Fortsetzung) wäre somit im Hinblick auf frühe Neolithisierungsprozesse, vielleicht sogar epi-paläolithische Wanderungen, relevant. Hier die Stichprobenergebnisse Nihali-Wolof:
http://maxwellsci.com/print/crjbs/v2-229-231.pdf
C. Griechisch - Mascoy - Guato - Wiyot, dunkelblau in der Karte: Mysteriöse transatlantische Verbindung, die transpazifisch als Tingit (Na Dene) - Ket (jenisseisch) - nordkaukasische Kette fast wieder an den Ausgangspunkt zurückkehrt. Der transpazifische Teil wird in der Dené-kaukasischen Theorie abgehandelt, die durch den World Language Tree offenbar teilweise Stützung erfährt (beachte aber, daß sich athabaskische Sprachen im World Language Tree auf einem separaten, weit entfernten Ast [dunkelgrün] finden). Transatlantische Kognate, in der obigen Sprachreihenfolge (fehlende Korrespondenz in Rot):
Fazit: Alle Stichproben liefern zumindest begründeten Verdacht auf lexikalische Nähe, in mehreren Fällen klare Anzeichen für intensivere Sprachbeziehung. Nicht alle Zweige kann und will ich erklären, aber einige, die mit pflanzen- und humangenetischen Befunden korrespondieren, werde ich in der Folge weiter beleuchten.
* http://pib.socioambiental.org/en/povo/guato/1973
Das entstandene Muster ist zugegebenermaßen nicht nut auf den ersten Blick verwirrend. Klar wird jedoch, daß, wenn auch nur ein Teil der lexikostatistisch ermittelten Beziheungen eingehenderer Überprüfung standhält, deutlich mehr auf den Ozeanen los war als in den Geschichtsbüchern steht. Und zwar nicht nur transpazifisch, ondern auch und v.a. über Indischen Ozean und Atlantik. Ins Blickfeld rücken insbesondere Neuguinea mit seiner hohen linguistischen Diversität, dazu (Alt-)Guinea, weniger Guyana, dafür aber das ebenfalls linguistisch hoch diverse Amazonien. Angemerkt sei, daß die transpazifischen Beziehungen v.a. von Neuguinea, daneben Südostasien (Tai-Kadai, Taiwan) ausgehen, während lexikostatistisch die meisten der "üblichen Verdächtigen" für die Erstbesiedlung Amerikas (Tungusen, Japaner, Ainu etc.) ihren Weg dorthin über Indischen Ozean und Atlantik fanden.
Ich bin nicht in die Details des für die Erstellung des Baums verwendeten Algorithmus eingestiegen. Stattdessen habe ich stichprobenmäßig ein paar der dort aufgezeigten Beziehungen nachkontrolliert. Hierzu als Vorbemerkungen:Zur Interpretation steht bereits im verlinkten Text:
Um Verwandschaften zu behaupten oder gar noch weitreichendere Schlüsse zu ziehen, ist der Baum keine Grundlage.If the two languages are geographically distant, their close lexical similarity is more likely explained by chance than by either inheritance or diffusion. Also, language isolates may join one another on a terminal branch because they have nowhere else to go in the tree, creating the illusion that exciting, new far-flung relations may be in evidence. One should be cautious in the interpretation of these cases.
- Die dem Baum zugrundeliegende Datenbank enthält idealerweise pro Sprache jeweils 40 Grundvokabeln. Nicht immer wurden die Vokabeln vollständig aufgnommen; teilweise lagen der lexikostatistischen Analyse nur 30 Vokabeln zu Grunde.
- Als "Faustregel" sind bis 5% lexikostatistische Übereinstimmung als zufälig anzusehen, bei über 10% wird von Sprachverwandschaft ausgegangen. Die kleine Grundgesamtheit der analysierten Vokabeln gibt Anlaß, diese Grenzen etwas höher anzusetzen. 3-4 halbwegs plausible Kognate solten es also auf jeden Fall sein, ab 6 Kognaten (~15-20%) liegen starke Indizien für Sprachverwandschaft vor.
In Erweiterung habe ich die spanische 100-Vokabel-Liste gegen Deutsch geprüft, wobei ich nun auch die o.g. Fälle als korrespondierend einbezog, und erhielt einem Wert von nur noch 31%. Dies zeigt, daß, trotz der geringen Grundgesamtheit, die verwendeten 40 Grundvokabeln tendenziell geeignet sind, einen zutreffenden Eindruck der lexikalischen Nähe zweier Sprachen zu vermitteln.
Nun zu den Stichproben:
A. Mande-Sprachen (Westafrika, Niger-Kongo) -- Mandi (Marienberg-Sprachen, Neuguinea), hellblau in der Karte: Die Namensähnlichkeit war verlockend, und die geograühische Relation interessant. Hier die mir plausibel bzw. spekulaitiv denkbar erscheinenden Kognate (Mandinka-Mandi, soweit nicht anders angegeben; Soninka ist eine weitere Mande-, Bungain eine weitere Marienberg-Sprache):
- ich: n - nak
- wir: n - nam
- Laus: yitE (Soninka) - ph~it (Bungain)
- Fisch: 5e - ungearra
- Blatt: janba - kamgas
- Haut: kulu - Ngulom
- Blut: farE (Son.) - yawarr (Bun.)
- Knochen: XotE (Son.) - niNgat (Bun.)
- Ohr: toro (Soninke) - tomba
- Auge: yaXE (Son.) - yai (Bun.)
- trinken: min - wyanal (aber men "Brust")
- Wasser: ji -wiya
- Feuer: yinbE (Son.) - yi (Bun.)
- Pfad: silia -supwe; kilE (Son.) - kh~at (Bun.)
- Nacht: wuro (Son.) - nuNgarap (Bun.)
- voll: fa - pay si
- neu: kuta - saketa
B. Nihali (Indien)- Wolof (Senegal), grünblau in der Karte: Nihali enthält etwa 25-30% vor-indoaryanisches, vor-dravidisches und vor-austrosiatisches Substrat, und gilt damit als bester Repräsentant frühneolithischer südasiatischer Sprachen (Indus-Kultur). Über mögliche Verbindung zum Sumerischen wird spekuliert. Linguistische Verbindung nach Westafrika (hier ohne transatlantische Fortsetzung) wäre somit im Hinblick auf frühe Neolithisierungsprozesse, vielleicht sogar epi-paläolithische Wanderungen, relevant. Hier die Stichprobenergebnisse Nihali-Wolof:
- Du: nye - ya (jeweils Anglizierung?)
- Eins: beida - benna
- Zwei: ir(-ar) - nj~ar
- Fisch: tsan - (d)jan
- Hund: sita - xaT
- Blatt: tsokob - xob
- Blut: tsorto - dereb
- Zunge: lai5 - lami5
- Hand: bokko - loxo (mit nicht notiertem, initialem Schnalzlaut)
- hören: tsekini - deg'n
- Stern: ipih~ilta - biddew
- Stein: kurup - xar (idg? vgl. dt. "hart")
- Pfad: day - mb~edda
- voll: bh~erya - baax "gut"
- neu: nava - ndaw "jung"
http://maxwellsci.com/print/crjbs/v2-229-231.pdf
C. Griechisch - Mascoy - Guato - Wiyot, dunkelblau in der Karte: Mysteriöse transatlantische Verbindung, die transpazifisch als Tingit (Na Dene) - Ket (jenisseisch) - nordkaukasische Kette fast wieder an den Ausgangspunkt zurückkehrt. Der transpazifische Teil wird in der Dené-kaukasischen Theorie abgehandelt, die durch den World Language Tree offenbar teilweise Stützung erfährt (beachte aber, daß sich athabaskische Sprachen im World Language Tree auf einem separaten, weit entfernten Ast [dunkelgrün] finden). Transatlantische Kognate, in der obigen Sprachreihenfolge (fehlende Korrespondenz in Rot):
- Ich: exo - ko7o - oyo -(fehlt)
- Du: esi - Leya7 - ohe - kh-il
- Wir: emis - neNko7o - goko - hinod
- Eins: ena - Lama - Cene - nakuc
- Zwei: 8y~o - a7net - duni -dit
- Mensch: an8~ropos - enLet -(fehlt) - (fehlt)
- Hund: sTilos - semh~eN - we - woyic
- Laus: psira - petem - pagu - (fehlt)
- Baum: 8end~ro - yarnet - ada - botih
- Haut: petsi - eNy~empehek - fE - wonokw~
- Blut: ema - ema -- ogw~a - kawik
- Knochen: kolkalo - eNeLkapok - olku - watkadot
- Horn: Teras - aNkepetek - ta - badod
- Zunge: xlosa - eNaLkok - CaZa - bit
- Hand: xeri - eNmek - ra - ehs
- Leber: ipar - eNh~ekh~ek - pE - (fehlt)
- hören: aku - neNleNay7~ - ku* - puSukiL, kanimiL
- sterben: ap - apak - Coga - dakw~
- Feuer: foty~a - taLa - ta - bas
- Nacht: nita - aLta7a -- afi - dacawal
- voll: plinis - aklaney7~o - pelno - esw, kurow
- neu: neos - aLnaNkok - binEg3 - (fehlt)
Fazit: Alle Stichproben liefern zumindest begründeten Verdacht auf lexikalische Nähe, in mehreren Fällen klare Anzeichen für intensivere Sprachbeziehung. Nicht alle Zweige kann und will ich erklären, aber einige, die mit pflanzen- und humangenetischen Befunden korrespondieren, werde ich in der Folge weiter beleuchten.
* http://pib.socioambiental.org/en/povo/guato/1973
It may well be (..) that guató is a derivation of guatá, a verb that in Guarani signifies walk, wander, travel and traverse, annotated (..) in order to indicate a canoe people with a high degree of spatial mobility.